
Dixième étape - Ajout des concordances aux tables HTML
Lors de l’étape précédente, nous avons vu comment extraire le contexte d’apparition de nos mots-clés. Dans cette étape, nous verrons comment nous avons recupéré les concordances. Les “concordances” représentent tous les tokens à droite et à gauche du mot-clé présents sur la même ligne. Les concordances sont présents sous la forme d’un tableau HTML qui est integré aux tableaux HTML principaux. Comme il y a un seul tableau de concordance par langue, la répétition du lien vers ce tableau est inutile mais nous l'avons gardé par souci d'accessibilité et de clareté. Les tableaux HTML dédiés aux concordances contiennent 3 colonnes où, au centre, on retrouve nos mots-clés et à droite et à gauche les occurrences des autres mots présents sur la même ligne :

Afin de pouvoir créer les tableaux HTML des concordances nous avons dû écrire un nouveau script bash nommé “concordances.sh”. Ce script va créer 4 nouveaux tableaux HTML, un par langue choisie pour ce projet, et va les stocker dans un dossier CONCORDANCE. Afin de créer les concordances, nous repartons des fichiers présents dans le dossier CONTEXTES, qui contiennent déjà la ligne précédente et suivante l'occurence du mot-clé. Ainsi, dans les premières lignes du script une variable “liste” est déclarée et elle va contenir les différents fichiers présents dans le dossier CONTEXTES au fur et à mesure du traitement effectué par deux boucles “for” imbriquées.
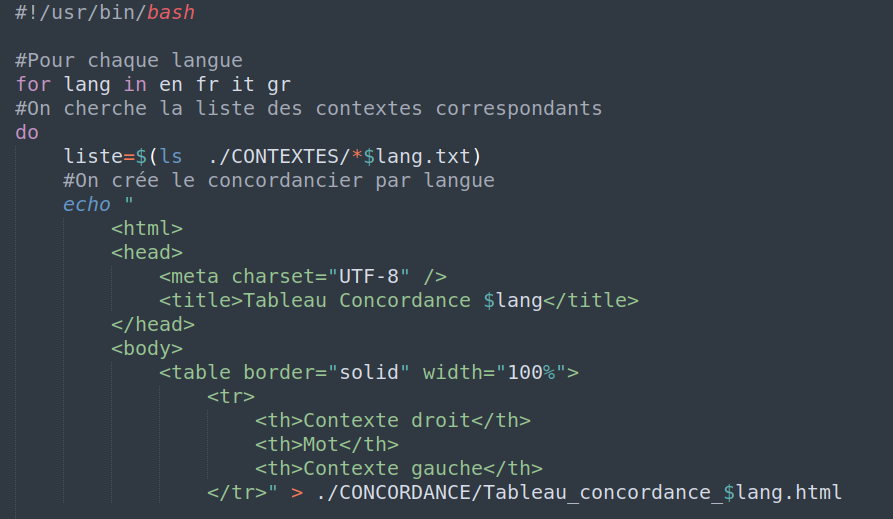
Ensuite, pour chaque fichier “contexte”, une commande “grep” va rechercher le pattern indiqué (nos mots-clés dans leurs différentes formes flexionnelles) en ignorant la casse avec l’option -i ; cette commande “grep” contient l’option -E (extended grep = “egrep”) et -T pour régler la tabulation des caractères en début de phrase et leur alignement. Nous avons ensuite effectué une commande “sed” sur la ligne contenant nos mots-clés. “sed” permet d’éditer rapidement des fichiers, tels que nos tableaux concordances HTML créés auparavant. Effectivement, lancer “sed” sur le résultat du “grep” en lui précisant un pattern spécifique à notre tâche nous a permis de séparer la ligne contenant nos mots-clés en contexte gauche, mot-clé et contexte droit :
