
Douzième étape - Nuage de mots
Afin de pouvoir générer un nuage de mots pour chacune des langues traitées dans notre projet, nous avons écrit un script python que nous allons présenter dans cet article.
Nous allons ici vous présenter étape par étape l’écriture de ce script python en expliquant la démarche et les choix éffectués.
1. Importations
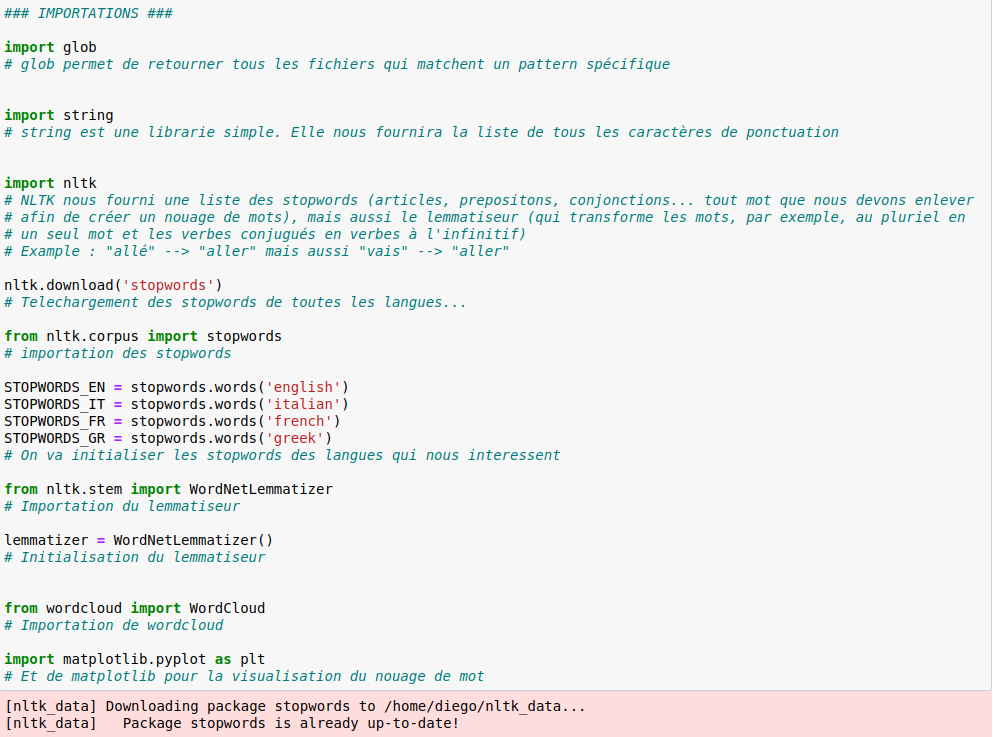
Nous avons importé les librairies suivantes:
-
glob
Glob nous permet de retourner tous les fichiers qui matchent un pattern spécifique. Cela est nécessaire afin de pouvoir faire lire au script tous les fichiers DUMPS-TEXT générés par notre script bash.
-
string
String nous fournira une liste des ponctuations qu’on éliminera par la suite après tokenisation.
-
nltk
Nltk nous fournit la plupart des fonctions dont on a besoin afin de normaliser les DUMPS-TEXT. Nous avons d'abord téléchargé tous les stopwords de toutes les langues du projet. Ensuite nous avons importé le lemmatiseur pour pouvoir éliminer par la suite les variations flexionnelles des mots présents dans les textes du corpus.
-
WordCloud
WordCloud nous permettera de générer le nuage de mot à partir de l’ensemble des DUMPS-TEXT de chaque langue.
-
matplotlib
Matplotlib nous serviva pour la visualisation du nuage de mot créé par WordCloud.
2. Normalisation
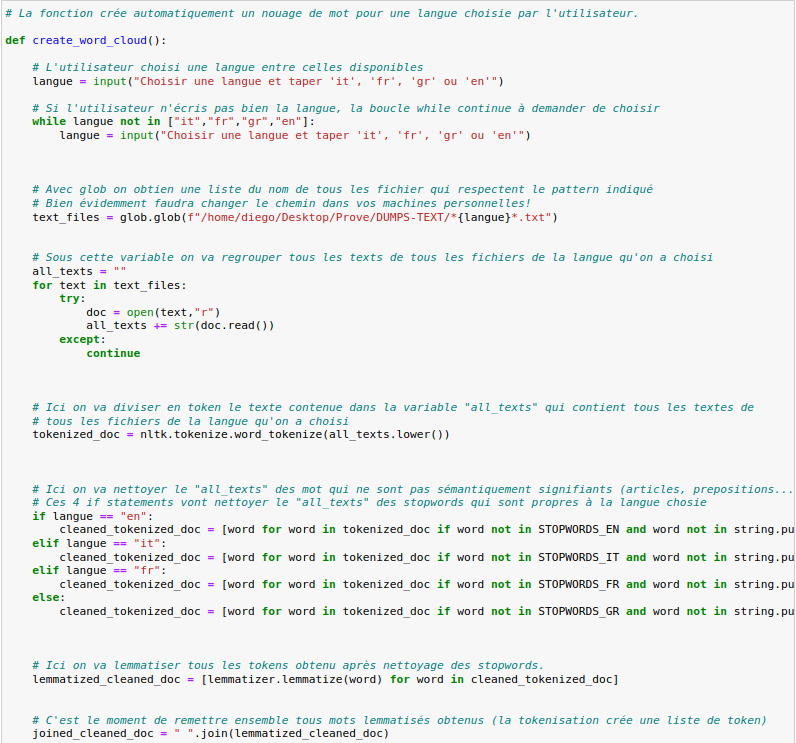
Avant de procéder à la normalisation de l’ensemble des DUMPS-TEXT, nous avons dû créer une variable “all_texts” qui comporte tous les contenus des fichiers DUMPS-TEXT. Glob nous permet de récupérer tous les textes et une boucle “for” les ouvre et les concatène dans la variable “all_texts”.
Ensuite on tokenise “all_texts” et on enlève la punctuation et les stopwords sur la base de la langue choisie. Le résultat obtenu est une liste de lexèmes qui, par la suite, est lemmatisée à travers le “lemmatizer” précédemment initialisé. L’ensemble des mots lemmatisés est ensuite stocké sous une seule variable “joined_cleaned_doc”.
3. Génération du WordCloud
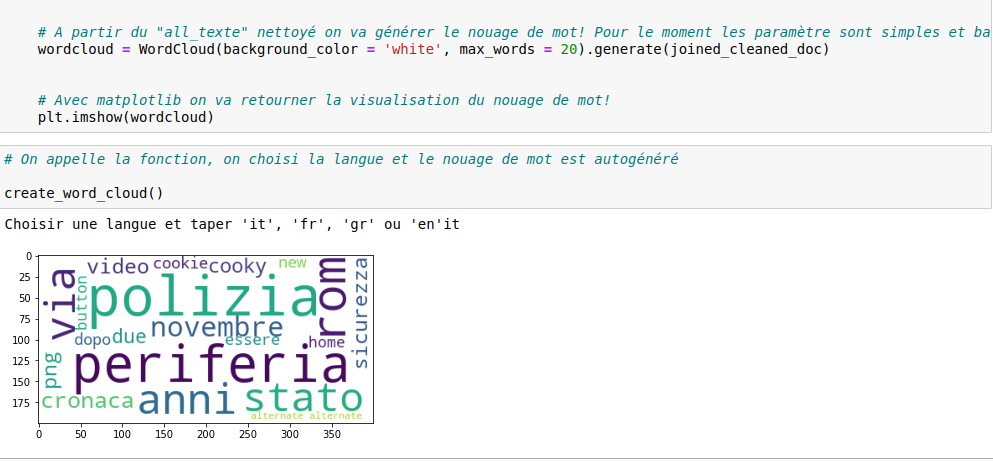
Finalement, la fonction “create_word_cloud” génère un nuage de mot à partir de “joined_cleaned_doc” avec des paramètres de visualisation choisis. Enfin, avec matplotlib nous allons pouvoir visualiser et sauvegarder l’image WordCloud générée.