Cinquième étape - Intégration des codes HTTP et des encodages aux tables
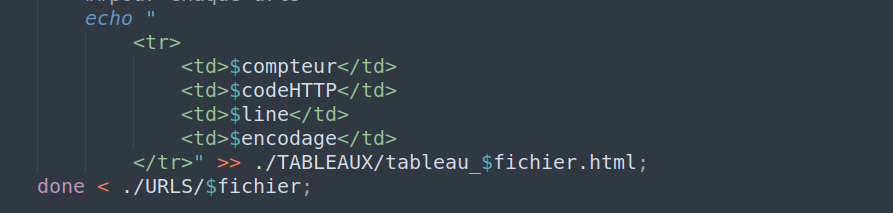
Suite à la création des tableaux HTML, nous avons continué progressivement leur remplissage. Dans cette étape nous avons ajouté aux tableaux HTML les codes HTTP des tous les urls et leur encodage. Pour cela, nous avons procédé de la façon suivante à la modification de notre script bash/HTML :
Code HTTP des urls
Pour chaque urls traité par la boucle “while”, nous avons exécuté une commande “curl” qui nous a donné le code HTTP de ces derniers. La ligne de code que nous avons écrite est la suivante :

Après la déclaration de la variable “codeHTTP”, nous lui avons attribué le résultat de plusieurs opérations effectuées sur les aspirations de “curl”. Pour que “curl” nous renvoie seulement le code HTTP de l’url traitée, nous avons choisi plusieurs options de "curl" disponibles :
- -b --cookie = pour accepter les cookies éventuels
- -A = spécification de l’user agent, en lien avec les cookies
- -L = permet à “curl” de suivre toutes les redirections
- -w = permet à “curl” de montrer l’output (le code HTTP) en sortie standard
- -o = permet de stocker la page aspirée dans un fichier spécifié
Une fois le code HTTP de l’url traitée stocké dans la variable “codeHTTP”, nous l’avons ajouté aux tableaux HTML créés lors de l’étape précedente. Il est important aussi de remarquer que les aspirations des tous les urls ont été stockées et triées dans un dossier appelé ASPIRATIONS.
Encodage des textes des urls
Afin de retrouver l’encodage des caractères des textes des articles constituants notre corpus, nous avons écrit la ligne de commande suivante :

Comme vu auparavant, ici aussi nous avons déclaré une variable “encodage” et nous y avons stocké le résultat d’une opération “curl”, “grep”,”cut” et “head” (dans cet ordre). Les options choisies pour “curl” cette fois-ci sont :
- -I = “curl” affiche seulement les headers
- -s = mode silence de “curl”
- -w = permet à “curl” de montrer l’output (l’encodage) en sortie standard
Toutefois, le résultat de “curl” n’était pas encore parfait car on devait encore isoler l’encodage sans que d'autres portions du texte que le header n’apparaissent. Pour cela, nous avons utilisé “grep” sur la sortie standard de “curl” avec les options suivantes :
- -i = “grep” ignore la casse
- -P = “grep” interprète le pattern fourni comme une expression régulière Perl
- -o = “grep” affiche seulement le texte qui matche le pattern fourni
À ce moment là, il nous fallait absolument éliminer le mot “charset=” pour garder uniquement la portion du texte qui suit. C’est donc avec “cut” que nous avons divisé la sortie de “grep” en deux, à partir du symbole “=”. Ensuite nous en avons recuperé la deuxième partie, c'est-à-dire l’encodage du texte de l’article, et nous avons ajouté la valeur de la variable "encodage" à nos tableaux HTML :